문제
https://programmers.co.kr/learn/courses/30/lessons/42587
코딩테스트 연습 - 프린터 | 프로그래머스
일반적인 프린터는 인쇄 요청이 들어온 순서대로 인쇄합니다. 그렇기 때문에 중요한 문서가 나중에 인쇄될 수 있습니다. 이런 문제를 보완하기 위해 중요도가 높은 문서를 먼저 인쇄하는 프린터를 개발했습니다. 이 새롭게 개발한 프린터는 아래와 같은 방식으로 인쇄 작업을 수행합니다. 1. 인쇄 대기목록의 가장 앞에 있는 문서(J)를 대기목록에서 꺼냅니다. 2. 나머지 인쇄 대기목록에서 J보다 중요도가 높은 문서가 한 개라도 존재하면 J를 대기목록의 가장 마지막에
programmers.co.kr
일반적인 프린터는 인쇄 요청이 들어온 순서대로 인쇄합니다. 그렇기 때문에 중요한 문서가 나중에 인쇄될 수 있습니다. 이런 문제를 보완하기 위해 중요도가 높은 문서를 먼저 인쇄하는 프린터를 개발했습니다. 이 새롭게 개발한 프린터는 아래와 같은 방식으로 인쇄 작업을 수행합니다.
1. 인쇄 대기목록의 가장 앞에 있는 문서(J)를 대기목록에서 꺼냅니다. 2. 나머지 인쇄 대기목록에서 J보다 중요도가 높은 문서가 한 개라도 존재하면 J를 대기목록의 가장 마지막에 넣습니다. 3. 그렇지 않으면 J를 인쇄합니다.
예를 들어, 4개의 문서(A, B, C, D)가 순서대로 인쇄 대기목록에 있고 중요도가 2 1 3 2 라면 C D A B 순으로 인쇄하게 됩니다.
내가 인쇄를 요청한 문서가 몇 번째로 인쇄되는지 알고 싶습니다. 위의 예에서 C는 1번째로, A는 3번째로 인쇄됩니다.
현재 대기목록에 있는 문서의 중요도가 순서대로 담긴 배열 priorities와 내가 인쇄를 요청한 문서가 현재 대기목록의 어떤 위치에 있는지를 알려주는 location이 매개변수로 주어질 때, 내가 인쇄를 요청한 문서가 몇 번째로 인쇄되는지 return 하도록 solution 함수를 작성해주세요.
제한사항
- 현재 대기목록에는 1개 이상 100개 이하의 문서가 있습니다.
- 인쇄 작업의 중요도는 1~9로 표현하며 숫자가 클수록 중요하다는 뜻입니다.
- location은 0 이상 (현재 대기목록에 있는 작업 수 - 1) 이하의 값을 가지며 대기목록의 가장 앞에 있으면 0, 두 번째에 있으면 1로 표현합니다.
입출력
priorities location return
| [2, 1, 3, 2] | 2 | 1 |
| [1, 1, 9, 1, 1, 1] | 0 | 5 |
알고리즘
def solution(priorities, location):
answer = 0
d2_prior = []
# 인덱스와 값을 따로 저장하기 위해서, 주어진 데이터를 2차원 배열의 형태로 바꾼다.
# 각 원소는 [처음에 주어진 인덱스, 값] 이러한 형태로 저장된다.
for i in range(len(priorities)):
d2_prior.append([i, priorities[i]])
i = 0
# d2_prior 배열의 원소가 더이상 없을 때까지 순회한다.
while d2_prior:
# d2_prior 배열의 0번째 원소를 꺼낸다.
temp = d2_prior.pop(0)
# 나머지 d2_prior 배열의 1번째 값과 temp의 1번째 값을 비교한다.
for i in range(len(d2_prior)):
# 만약 d2_prior배열의 i번째 원소의 1번째 값이 더 크다면, 더 중요한 문서가 뒤에 있다는 뜻이다.
# 그러므로 출력하지 않고 d2_prior배열의 맨 뒤로 보낸다.
if temp[1] < d2_prior[i][1]:
d2_prior.append(temp)
continue
# 그렇지 않고, 현재 temp의 1번쨰 값이 가장 크다면, temp문서가 가장 중요하다는 뜻이므로 출력한다.
else:
# 문제에서 주어진 location과 temp의 0번쨰 값이 일치한다면, 그때 멈춘다.
if temp[0] == location:
break
else:
# 그렇지 않다면, answer의 값을 1 증가시킨다.
answer += 1
return answer + 1설명
- 문제를 풀려면, 주어진 priorities 배열의 값 뿐만 아니라 해당 값의 처음 인덱스까지 같이 알고 있어야 한다. 따라서, 2차원 배열 형태로 자료구조를 수정한다. 수정한 배열인 d2_prior는
[[처음 주어진 인덱스, 값] , [처음 주어진 값, 인덱스], ... [처음 주어진 값, 인덱스]]
의 형태를 갖는다. - d2_prior배열을 순회하면서, 0번째 값을 꺼내서 temp에 저장한다.
- temp[1]번째 원소의 값과, d2_prior[i][1]번째 값을 비교한다. 만약 temp[1]번째 원소의 값보다 큰 값이 있다면, 더 중요한 문서가 뒤에 있다는 뜻이므로, 출력하지 않고 temp를 다시 d2_prior의 뒤에 append한다
- 그렇지 않다면, temp는 d2_prior에서 pop된 상태이다. 이 상태에서, temp[0]의 값이 파라미터로 주어진 location과 같다면 원하는 문서가 출력된 것이므로 break한다. 그렇지 않고 두 값이 다르다면, answer의 값을 1 늘려준다.
- answer 에 1을 더한 값을 리턴한다.
결과
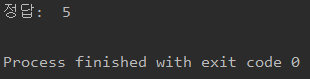
후기
그냥 냅다 2중 for문을 돌리기 보다는, 다른 형태의 자료구조인 딕셔너리를 사용해서 풀려고 했다. 그러나 배열의 인덱스와 값을 동시에 알고있게끔 한다는 게 쉽지가 않아서, 그냥 늘 풀던대로 풀었다. 다행히 입력이 100개 미만이라, N^2으로 풀어도 상관은 없었다. 다른 사람들의 풀이를 봤는데, 좀 더 간결하게 짰다는 것만 뺴면 기능과 방식은 나와 비슷했다. 그런데 인상 깊었던 다른 풀이가 있었는데, 밑에서 다루겠다.
다른 풀이
def solution2(p, l):
ans = 0
m = max(p)
while True:
v = p.pop(0)
if m == v:
ans += 1
if l == 0:
break
else:
l -= 1
m = max(p)
else:
p.append(v)
if l == 0:
l = len(p)-1
else:
l -= 1
return ans위의 방식에서는 다음과 같은 방법으로 문제를 해결했다.
- p배열에서 최대 값을 m에 저장한다.
- p배열의 0번쨰 값을 pop해서 v에 저장한다.
- 만약 m == v 라면, 즉 p배열에서 중요도가 가장 높은 문서와 방금 꺼낸 문서의 중요도가 같다면, m은 가장 먼저 출력되어야할 문서라는 뜻이다. 따라서, answer의 값을 1 증가시킨다.
그리고, 문제에서 정한 location의 값이 0이라면, 반복을 멈춘다. (정답이 나온 경우)
그렇지 않다면, l의 값을 1 감소시킨다. 왜 이렇게 하냐면
주어진 배열이 [p1, p2, p3, p4]이고 loccation값이 3이었다면, p1이 pop 된 상태이므로, 배열은 [p2, p3, p4] 가 되는데, 이렇게 배열의 길이가 줄어들면 p4의 위치 또한 3이 아니라 2가 되는것이기 때문이다.
그러고 나서, 남은 배열에서 다시 최대값을 뽑아서 m에 저장한다. - m != v 라면(m은 배열에서의 최대값이고, v는 방금 pop한 값), v보다 중요한 문서가 뒤에 있다는 뜻이므로, p배열에 append한다.
그리고, 문제에서 정해준 location값이 0이라면, 위의 경우에서 이 값 또한 문서의 맨 뒤로 이동하므로, len(p)-1 을 실행하게 된다.
location값이 0이 아니라면, l의 값을 1 감소시킨다. 위에서 설명했듯이, 배열을 한칸씩 왼쪽으로 당기는 것이다.
두 코드의 실행시간을 비교해봤다.

비교를 해보니, 다른 사람의 코드가 내 코드보다 실행 시간이 2~3배 정도 적은 것을 알 수 있었다. 이 정도 차이가 의미가 있는지 없는지 잘은 모르지만, 코딩테스트에서는 효율성 또한 고려를 해줘야 하므로, 가벼이 지나치지 않아야한다. 그래서 보니, 내 코드는
- 주어진 데이터를 다시 만들어야 함
- 2중 for문 사용
이 2가지 문제가 있는 것 같았다. 좀 더 효율적인 방법으로 풀려면 항상 더 많이 생각하고 답을 내놓아야겠다.
'공부 > 알고리즘' 카테고리의 다른 글
| [프로그래머스 해시]베스트 앨범 - Python3 (0) | 2020.01.28 |
|---|---|
| [프로그래머스 스택/큐]쇠 막대기 - Python3 (0) | 2020.01.28 |
| [프로그래머스 스택/큐]기능 개발 - Python3 (0) | 2020.01.13 |
| [프로그래머스 스택/큐]다리를 건너는 트럭 - Python3 (0) | 2020.01.13 |
| [프로그래머스 스택/큐]탑 - Python3 (0) | 2020.01.13 |



