전 게시물들에서,
- 그래프 자료구조
- 그래프 순회 알고리즘 중 BFS
- 그래프 순회 알고리즘 중 DFS
- 위상 정렬
에 대해 알아보았다. 이번 시간에는 최소 신장트리를 만드는 알고리즘인 프림 알고리즘에 대해 알아보자.
신장 트리
신장 트리란, 주어진 그래프의 정점의 집합과 간선의 집합을 원소로 가지는 부분집합, 즉 sub-graph 중에서, 다음 조건을 만족하는 sub-graph(트리)를 말한다.
- 그래프 내의 모든 정점을 포함한다.
- 사이클이 존재해선 안된다. (사이클이란, 이동 가능한 경로 중, 출발점과 도착점이 같은 경로를 말한다.)
N개의 정점을 가진 신장 트리는 N-1개의 정점을 가진다. 이러한 신장 트리는, 최소의 링크를 사용하는 네트워크를 구축하는데에 쓰인다. 신장 트리는 한 그래프 내에 여러 개가 존재할 수 있다. 그 중, 포함된 간선의 가중치의 합이 가장 작은 신장 트리를 최소 비용 신장 트리라고 한다.
그냥 신장 트리를 구하는 것은 DFS알고리즘으로도 구할 수 있다. 그러나, 신장 트리 중 가장 의미 있는 것은 최소 비용 신장 트리이다.
최소 비용 신장 트리
주어진 그래프에서 만들 수 있는 신장 트리 중, 그 값이 가장 작은 신장 트리를 말한다. 최소 신장 트리는 통신망, 도로망같은 네트워크를 최소의 비용으로 구축하는 문제의 답을 말한다. 주로 나오는 예제는 다음과 같다.
- 도로 건설: 도시들을 모두 연결하면서 도로의 길이를 최소가 되도록 하는 문제
- 정기 회로: 단자들을 모두 연결하면서, 전선의 길이를 가장 최소로 하는 문제
- 통신: 전화선의 길이가 최소가 되도록 하는 전화 케이블 망을 구성하는 문제
- 배관: 파이프를 모두 연결하면서, 파이프의 총 길이를 최소로 하는 문제
위의 예제들은 공통적으로, 정점들(도로, 전화기 등)을 최소의 간선, 최소의 비용(간선의 가중치)으로 모두 연결하는 것을 목표로 한다. 앞으로 이러한 문제를 본다면, 프림 알고리즘 또는 크루스칼 알고리즘을 활용할 수 있다.
프림 알고리즘
프림 알고리즘은 다음과 같은 아이디어를 사용한다.
- 시작 정점에서부터 출발해서, 신장 트리 집합을 단계적으로 확장한다.
- 시작 단계에서는 시작 정점만이 신장 트리 집합에 포함된다.
- 신장 트리 집합에 인접한 정점 중에서, 최저 간선으로 연결된 정점을 선택해서 신장 트리 집합에 추가한다.
- 이 부분을 잘 이해하지 못하면 앞으로 좀 헤맬 것이다. 좀 더 풀어서 설명하면, 반복을 통해서 신장 트리 집합을 만들 건데, 기존에 신장 트리 집합에서 도달할 수 있는 정점들 중에서, 가장 낮은 가중치로 도달할 수 있는 정점을 선택해서 신장 트리 집합에 추가한다는 뜻이다.
- 신장 트리 집합이 n-1개의 간선을 가질 때까지 반복한다.
말로만 보면 잘 모를것 같아서, 이를 그림으로 표현하면 다음과 같다.
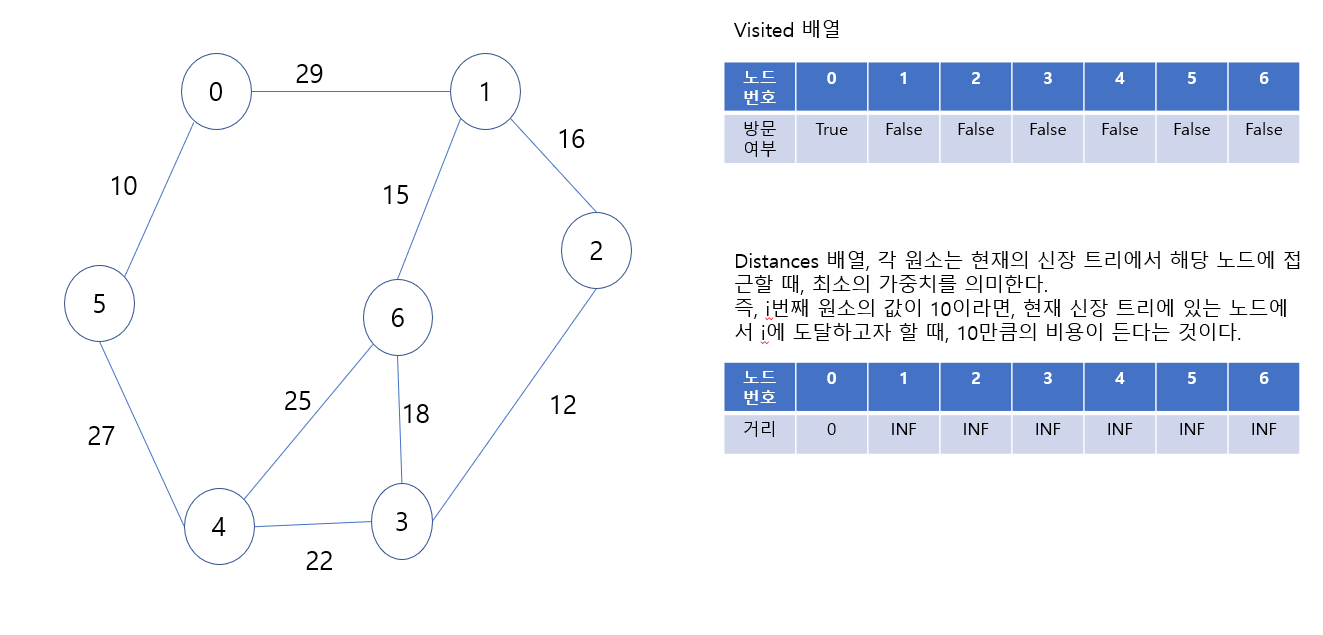
위 그림은 초기 상태이다. 반복을 하면서, 최소 신장 트리에 포함되는 노드를 주황색으로 칠할 것이다. 그리고 각 단계마다 신장 트리에 포함되는 노드를 visited배열에 True로 표시할 것이다. 그리고, 한 노드가 신장 트리에 포함됨에 따라, 현재 신장 트리에서 해당 노드를 포함하는데 드는 비용의 최솟값을 distances배열의 각 원소에 표현하고, 글씨 색을 빨간 색으로 칠할 것이다.
시작하는 노드는, 아무 노드나 해도 상관 없다. 왜냐하면, 최소 신장 트리는 여러개일 수 있지만, 그 최소 신장 트리가 나타내는 비용의 총 합은 한 가지이기 때문이다. 그래서 시작 노드는 일단 0으로 하겠다.

시작 노드를 최소 신장 트리에 포함했다. 그리고, 0번 노드를 방문했음을 표시했고, distances[0]의 값을 0으로 했다. 그리고 0에서 어떤 노드로 갈지를 정해야 하는데, 0에서 갈 수 있는 노드는 1번 노드와 5번 노드이다. 그런데 0번에서 1번으로 가는데는 29의 비용이 필요하고, 0번에서 5번으로 가는데는 10만큼의 비용이 필요하다. 5번 노드로 가는 것이 비용이 더 적게 듬으로, 5번 노드를 선택한다. 그럼 아래 그림이 나온다
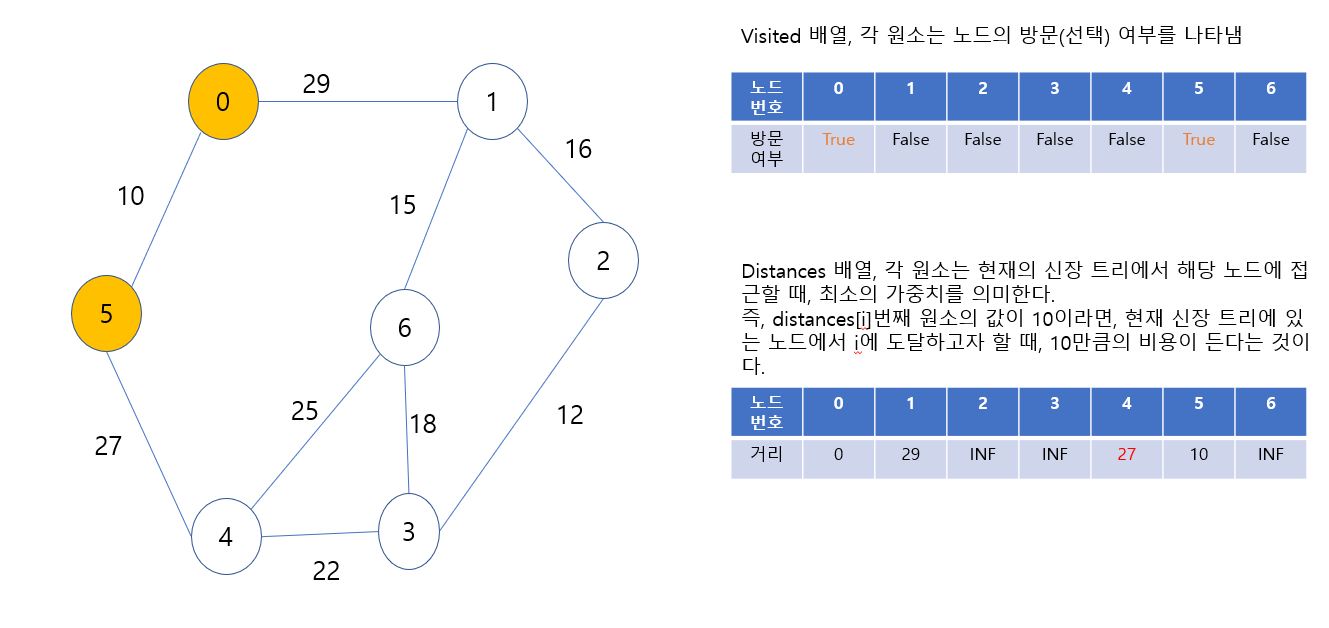
5번 노드가 신장 트리에 포함되었고, 방문했음을 표시했다. 또한, 5번으로부터 갈 수 있는 노드인 4번 노드의 distance 값이 INF에서 27로 갱신되었다. 다음에 최소 신장 트리에 포함시킬 노드는 1번 또는 4번 노드인데, 4번 노드로 가는 가중치가 가장 작으므로, 4번 노드를 포함시킨다.

4번 노드가 신장 트리에 포함되었고, 방문했음을 표시했다. 또한, 4번으로부터 갈 수 있는 노드인 3번 노드, 6번 노드의 distance 값이 INF에서 각각 22, 25로 갱신되었다. 다음에 최소 신장 트리에 포함시킬 노드는 1번 또는 3번 또는 6번 노드인데, 3번 노드로 가는 가중치가 가장 작으므로, 3번 노드를 포함시킨다.
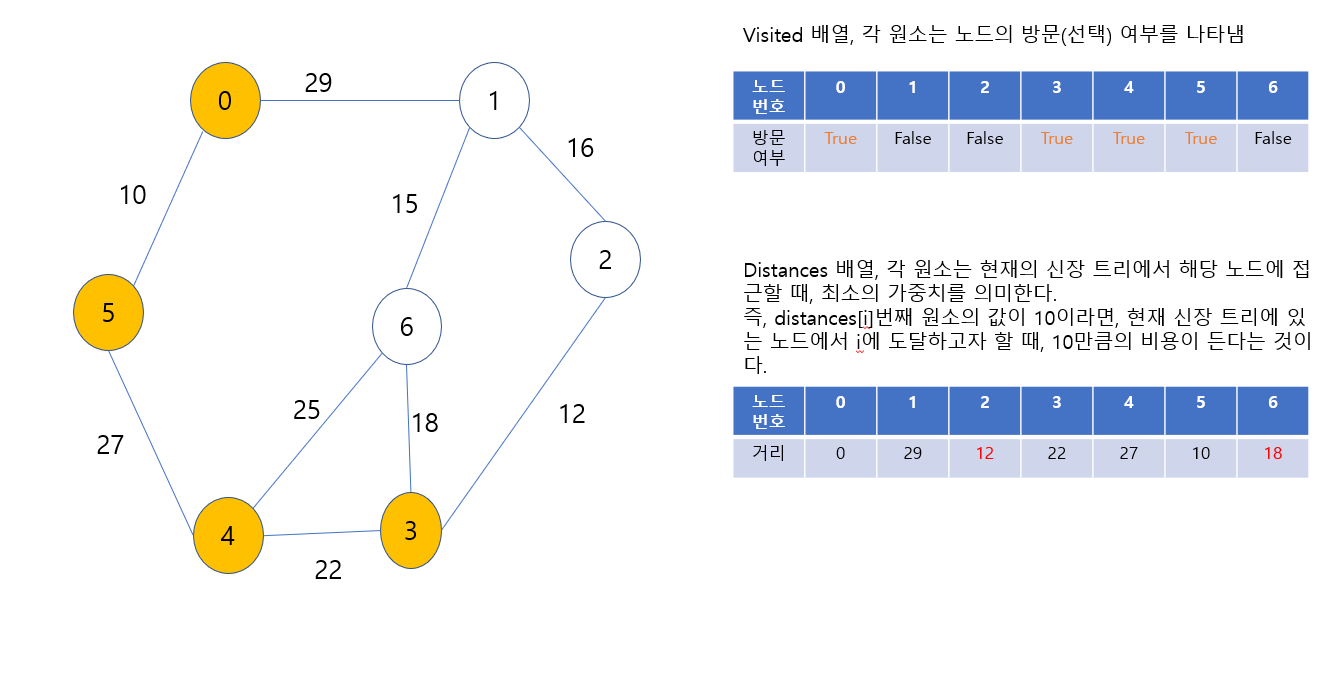
3번 노드가 신장 트리에 포함되었고, 방문했음을 표시했다. 또한, 3번으로부터 갈 수 있는 노드인 2번, 6번 노드의 distance값이 INF에서 12로, distances[6]의 값은 25에서 18로 갱신되었다. 다음에 최소 신장 트리에 포함시킬 노드는 1번 또는 2번 또는 6번 노드인데, 2번 노드로 가는 가중치가 가장 작으므로, 2번 노드를 포함시킨다.
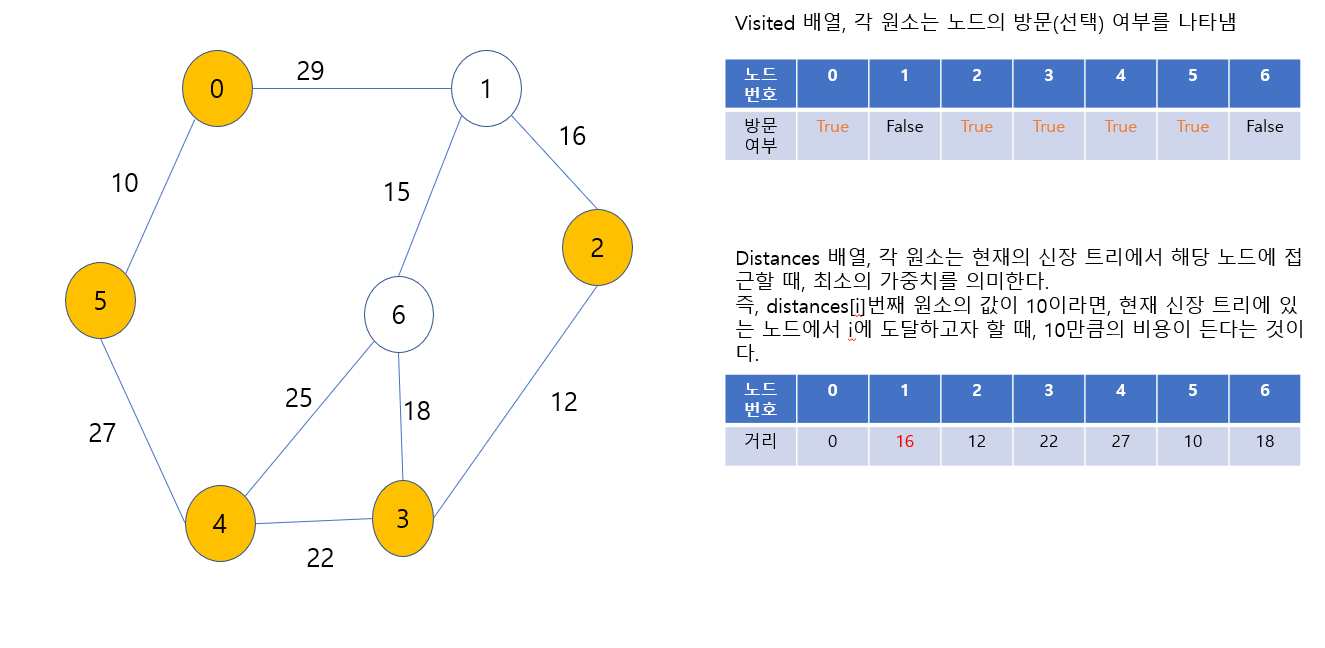
2번 노드가 신장 트리에 포함되었고, 방문했음을 표시했다. 또한, 2번으로부터 갈 수 있는 노드인 1번 노드의 distance값이 29에서 16로 갱신되었다. 다음에 최소 신장 트리에 포함시킬 노드는 1번 또는 6번 노드인데, 1번 노드로 가는 가중치가 가장 작으므로, 1번 노드를 포함시킨다.

1번 노드가 신장 트리에 포함되었고, 방문했음을 표시했다. 또한, 1번으로부터 갈 수 있는 노드인 6번 노드의 distance값이 18에서 15로 갱신되었다. 다음에 최소 신장 트리에 포함시킬 노드는 6번 노드이다.
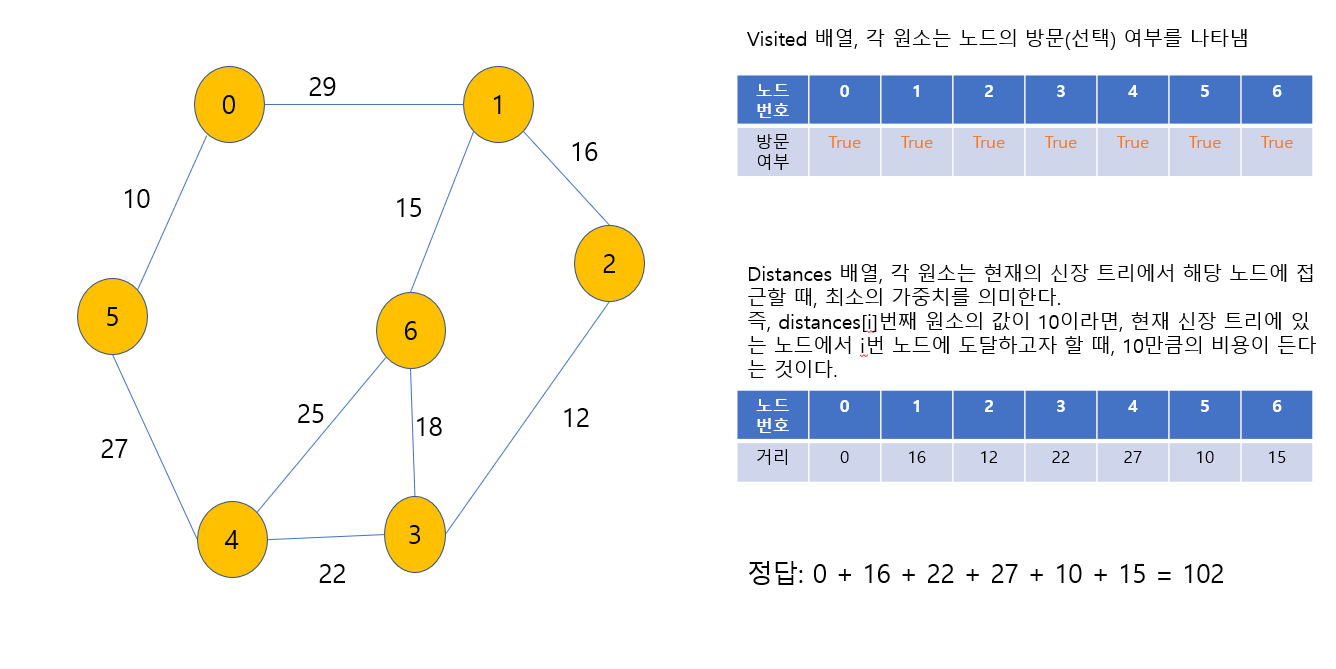
6번 노드가 포함되었다. 이로써 완성된 최소 비용값은 distances배열의 합인 102이고, 신장 트리는 다음과 같다.

위의 최소 신장 트리는 아래와 같은 과정으로 만들어진다.

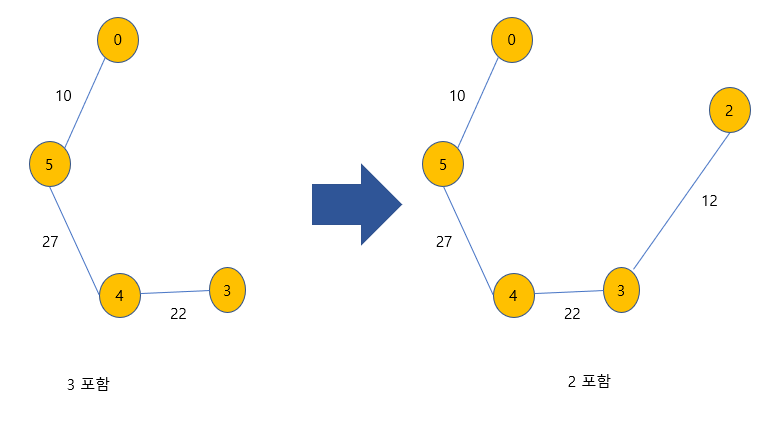

과정은 위에서 아래로, 왼쪽에서 오른쪽으로 흘러간다.
의사코드는 아래와 같다.
- 신장 트리에 시작 정점을 포함시킨다.
- 노드의 갯수만큼 아래를 반복한다
- 현재 신장 트리에서 도달할 수 있는 노드 중 간선의 가중치값이 가장 작은 노드를 선택해서 신장 트리에 포함시킨다
- 그 노드에서 갈 수 있고 아직 방문하지 않은 노드가 있다면, 그 노드(y)의 distance값을 갱신한다.
아주 간단하다. 이제 코드를 살펴보자.
알고리즘
"""
주어진 인접행렬에서, Prim 알고리즘을 통해 최소 신장 트리를 구한다.
입력: 인접 행렬, 시작 정점
출력: 시작 정점에서 만든 최소 신장 트리
알고리즘:
1. dist 배열을 INF로 초기화
2. dist[start] = 0
3. 우선 순위 큐 queue에 모든 정점 삽입(우선 순위는 dist[])
4. i는 0부터 n-1까지 반복
1). u에 weight가 가장 작은 간선 삽입
2). u의 인접 정점들인 v를 반복
v가 Q의 원소이고, weight[u][v] < dist[v]라면
dist[v]에 weight[u][v]를 할당
설명:
0. 프림 알고리즘은 시작 정점을 최초의 신장 트리로 놓는다.
1. 시작 정점만이 포함된 신장 트리에서, 더 포함시킬 수 있는 노드들을 찾아놓는다.
2. 더 포함시킬수 있는 노드 중, 비용(가중치)가 가장 작은 노드를 포함시킨다.
3. 2에서 포함된 정점에서 가장 낮은 비용으로 도달할 수 있는 노드를 찾아서,
그 노드를 신장 트리에 포함시킨다.
"""
INF = 999
adj_mat = [[0, 29, INF, INF, INF, 10, INF],
[29, 0, 16, INF, INF, INF, 15],
[INF, 16, 0, 12, INF, INF, INF],
[INF, INF, 12, 0, 22, INF, 18],
[INF, INF, INF, 22, 0, 27, 25],
[10, INF, INF, INF, 27, 0, INF],
[INF, 15, INF, 18, 25, INF, 0]]
node_num = len(adj_mat)
visited = [False] * node_num
distances = [INF] * node_num
"""
get_min_node 메소드
1. i가 0부터 node 갯수만큼 반복한다.
i 노드가 방문한 적 없는 노드라면,
v에 i를 저장한다.
멈춘다.
2. i가 0부터 node_num 만큼 반복한다.
i가 방문하지 않았고, 방금 저장한 v보다 비용이 작은(기존의 신장트리로부터의 거리가 작은)
노드 i를 발견한다면
v에 i를 덮어쓴다.
v를 리턴한다.
"""
def get_min_node(node_num):
print("get_min_node 함수 진입했다")
for i in range(node_num):
if not visited[i]:
v = i
break
print("아직 방문하지 않은 v: ", v)
for i in range(node_num):
if not visited[i] and distances[i] < distances[v]:
print("i: ", i, "\tv: ", v)
print("distaces[i], distances[v]: ", distances[i], distances[v])
v = i
print("아직 방문 안됐고, 기존 v보다 distances값 작은 정점 발견 교체, 최종 v: ", v)
return v
def prim(start, node_num):
# distances 배열과 visted 배열 초기화
for i in range(node_num):
visited[i] = False
distances[i] = INF
# 시작노드의 distance 값을 0으로 초기화
distances[start] = 0
for i in range(node_num):
print("--------------------")
print("prim 메소드 내부 반복 시작, 반복 회차: ", i)
node = get_min_node(node_num)
visited[node] = True # node 를 방문했다 표시
print("\nget_min_node 에서 선택된 노드: ", node)
for j in range(node_num):
if adj_mat[node][j] != INF:
if not visited[j] and adj_mat[node][j] < distances[j]:
print("방금 포함된 ", node, "와 연결되어있고, "
"아직 방문하지 않았으며, "
"기존의 신장트리로부터의 거리보다 작은 경로가 발견되어, "
"distances[j]의 값을 갱신해야 하는 j: ", j)
distances[j] = adj_mat[node][j]
print("distances: ", distances)
print("--------------------")
print(prim(0, node_num))
print("distances: ", distances)
print("minimum cost: ", sum(distances))
코드를 설명하면 아래와 같다.
- vistied 배열과 distances배열을 각각 False, INF(무한대)로 초기화 한다.
- ditances[start]의 값을 0으로 초기화한다.
- 인덱스인 i가 (0부터 node의 갯수-1) 만큼 아래 과정을 반복한다.
- 현재 신장 트리에서 도달할 수 있는 노드 중, 가장 비용이 작은 노드를 선택해서 node에 저장한다.
- visited[node]를 True로 한다
- 인덱스 j가 0부터 노드의 갯수-1 만큼 아래 과정을 반복한다.
- node로부터 갈 수 있는 정점들 중에서, node와 연결되어 있고, 아직 방문하지 않았으며, 기존의 신장트리로부의 거리보다 distance 값이 작은 정점이 있다면, 그 정점의 distance값을 갱신한다.
위 코드를 실행하면 아래와 같은 결과가 나온다.

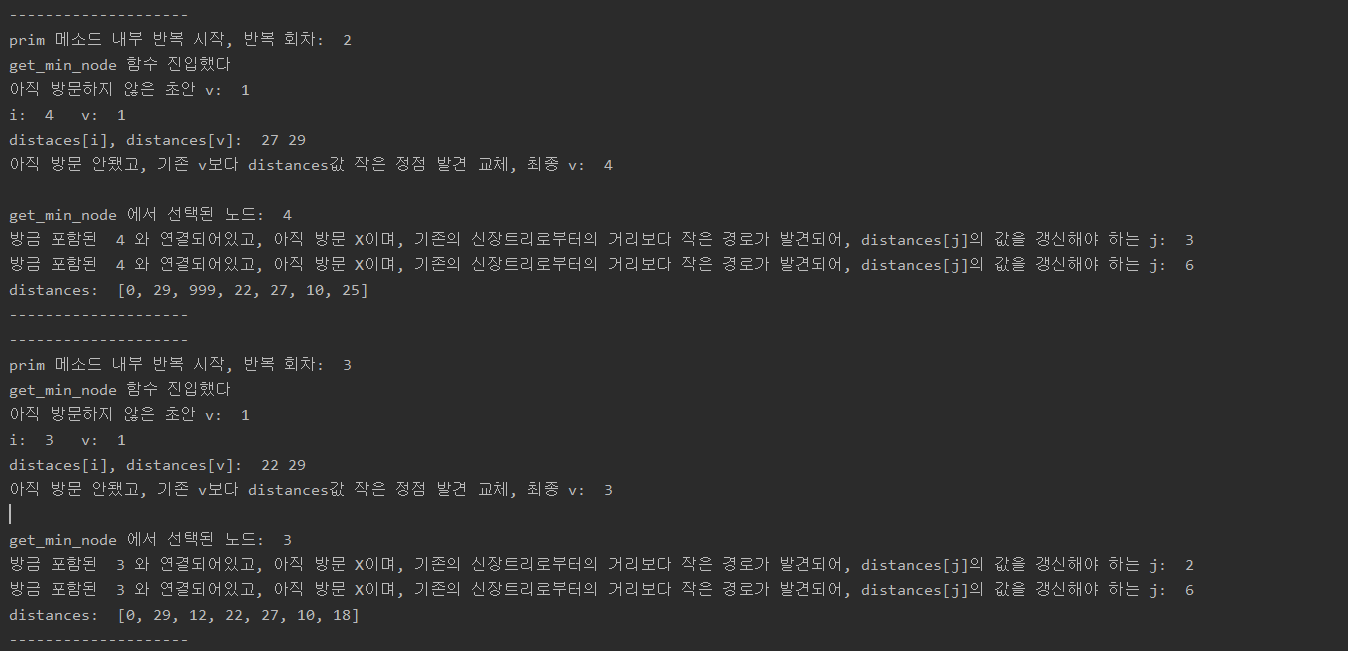

매 반복마다
- 반복 회차
- get_min_node를 통해 얻은 노드 번호
- get_min_node를 통해 얻는 노드에서 갈 수 있는 노드 중, distance값을 갱신해야 하는 노드 번호
- 갱신된 distances 배열의 값
위의 값들을 출력하게 했다. 아래에 프린트문을 지운 코드도 첨부할테니, 너무 난잡하다 싶으면 그걸 보도록 하라.
INF = 999
adj_mat = [[0, 29, INF, INF, INF, 10, INF],
[29, 0, 16, INF, INF, INF, 15],
[INF, 16, 0, 12, INF, INF, INF],
[INF, INF, 12, 0, 22, INF, 18],
[INF, INF, INF, 22, 0, 27, 25],
[10, INF, INF, INF, 27, 0, INF],
[INF, 15, INF, 18, 25, INF, 0]]
node_num = len(adj_mat)
visited = [False] * node_num
distances = [INF] * node_num
def get_min_node(node_num):
for i in range(node_num):
if not visited[i]:
v = i
break
for i in range(node_num):
if not visited[i] and distances[i] < distances[v]:
v = i
return v
def prim(start, node_num):
# distances 배열과 visted 배열 초기화
for i in range(node_num):
visited[i] = False
distances[i] = INF
# 시작노드의 distance 값을 0으로 초기화
distances[start] = 0
for i in range(node_num):
node = get_min_node(node_num)
visited[node] = True # node 를 방문했다 표시
for j in range(node_num):
if adj_mat[node][j] != INF:
if not visited[j] and adj_mat[node][j] < distances[j]:
distances[j] = adj_mat[node][j]
print(prim(0, node_num))
print("distances: ", distances)
print("minimum cost: ", sum(distances))
프림 알고리즘의 시간 복잡도는 O(N^2)이다. 크루스칼 알고리즘은 O(E log(E))이다 (N은 노드의 갯수, E는 간선의 갯수).따라서, 희박한, 즉 간선의 갯수가 적은 그래프인 경우는 크루스칼 알고리즘을 사용하는 것이 유리하고, 밀집한(간선의 갯수가 많은)그래프라면 프림 알고리즘을 사용하는 것이 좋다.
이렇게 프림 알고리즘에 대해 알아봤다. 최소 신장 트리는 문제로 내기 넘넘 좋은 구조이므로, 이 풀이를 통해 코테를 찢어버리도록 하자 ~
'공부 > 알고리즘' 카테고리의 다른 글
| [알고리즘 자습]그래프(Graph) - 3. 위상 정렬, 파이썬(Python3) (0) | 2020.03.04 |
|---|---|
| [알고리즘 자습]그래프(Graph) - 2. DFS(깊이 우선 탐색)의 정의와 활용, 예제, 파이썬(Python3) (1) | 2020.03.04 |
| [알고리즘 자습]그래프(Graph) - 1. BFS(너비우선탐색)의 정의와 활용, 예제, 파이썬(Python3) (1) | 2020.03.04 |
| [알고리즘 자습]그래프(Graph) - 0. 자료 구조 (0) | 2020.02.28 |
| [프로그래머스 탐욕법]저울 - Python3 (0) | 2020.02.28 |



